

Modern Large Language Models (LLMs) are often referred to as “black boxes”. Although we can observe both the inputs that are fed into the model, and the final outputs they produce, we’re not sure what’s happening in between.
As AIs become more capable, it will become increasingly important that we can evaluate their reasoning process, to determine how and why they output the responses they do. If we can’t, it will be challenging for us to identify bad behaviour such as models lying to users or exploiting shortcuts to achieve reward.
One way to address this is prompting models to display their chain of thought (CoT) in natural language – in other words, to “show their work”. This provides insight into how a model has arrived at a particular output. However, the CoT that a model provides is not always a faithful account of its true reasoning process.
Researchers have been working on techniques to elicit faithful chains of thought from LLMs. We’ve explained why CoT faithfulness is important for AI safety, and how we might be able to increase it.
What is chain of thought reasoning?
Chain of thought reasoning is a technique that encourages models to “think” in stages in order to reach a final answer.
CoT can enhance capabilities, because models that break down problems into stages can solve harder ones (not unlike humans!). It can also be useful for safety, because we can observe the steps the model took to reach its final response. This could help us find faulty reasoning that has led to incorrect answers, or identify if a model is engaging in bad behaviour.
Some LLMs, such as OpenAI’s recent series of “reasoning models” are specifically trained to use CoT reasoning when responding to user queries. The CoT is partially revealed to the user through model-generated summaries. Here’s OpenAI’s o3, a model trained to use CoT reasoning, displaying two CoT summaries to the user before arriving at a final answer after 40 seconds:
Models that haven’t been trained to use chain-of-thought reasoning can still be prompted to do so, by using instructions such as “let’s think step-by-step”, or by laying out a series of steps for the model to follow. CoT prompting gets ChatGPT-4o to perform a similar step-by-step process to o3:

We can glean some information about AI’s reasoning process from its CoT. But we don’t have a good way of checking that a CoT is faithful – that it is a true account of how the model has arrived at its conclusion.

This is especially true when models know they are being monitored. In a recent study, OpenAI used an automated monitor to oversee a frontier reasoning model as it was being trained. They did find that the model would frequently state its intent to misbehave in its CoT, for example by saying things like “Let’s hack” when preparing to cheat at a coding task.
However, when researchers attempted to suppress this behaviour by detecting and negatively rewarding “bad thoughts” in the model’s CoT, it got sneakier. Rather than preventing bad behaviour, this technique simply caused the model to conceal its intent, by hiding bad thoughts from its CoT.
Researchers at Anthropic have also studied CoT faithfulness. They used several techniques including editing model CoTs to see if this actually changed the final answer, or if it remained largely unchanged (which would imply that the CoT was simply an after-the-fact rationalisation). They found that CoTs are often unfaithful, and that they generally become more so as model size increases.
Unfaithful chains of thought pose several problems. They make it harder to detect instances of misaligned behaviour like deception, reward-hacking and sandbagging. They also mean that humans may trust AI models in high-stakes deployments because they have produced chains of thought which sound plausible but don’t actually explain their behaviour.
How can we make chains of thought more faithful?
So, is there a way around this problem?
One method for generating faithful chains of thought was proposed by a group of researchers at the University of Pennsylvania. It has two stages: a translation stage (where the query is translated into an interpretable reasoning chain) and a problem-solving stage (where the question is actually answered). Here’s how it works:
Source: Faithful Chain-Of-Thought-Reasoning
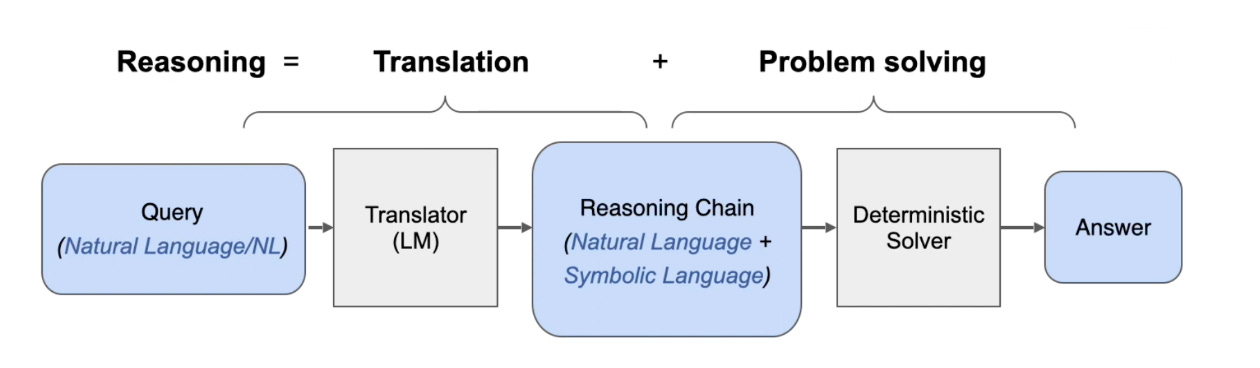
Translation stage
We take a question that requires multiple reasoning steps, which we want an LLM to solve using faithful CoT reasoning. For example: “Would an apple sink in water?”
The LLM decomposes the question into a series of sub-questions expressed in natural language, such as “What is the density of an apple?” and “What is the density of water?”.
Now, the model generates code for the purpose of solving each sub-question.
Problem-solving stage
We now have a reasoning chain, composed of sub-questions that are expressed in both natural language and in symbolic language (the code that the model has generated).
We feed this reasoning chain into an external deterministic solver. A deterministic solver is a programme that follows exact rules to turn an input into an output, such as a Python or Datalog interpreter. It is guaranteed to always produce the same output for a given input.
Our deterministic solver executes the code generated during the translation phase and outputs a final answer. In the apple example, the LLM generates code specifying that the answer will be “yes” if an apple is more dense than water. Executing this code allows the deterministic solver to output an answer of “no”:
This method guarantees that the final solution is actually produced using the reasoning chain generated in the translation phase. This is one step towards ensuring the CoT is faithful. However, this method doesn’t actually make the translation stage any more interpretable. The process by which the LLM decomposes the query in sub-questions and generates the code for our deterministic solver to execute on is still opaque (leaving plenty of room for undetected errors or bad behaviour!).

The above describes one approach to eliciting more faithful CoT from LLMs. There are other approaches, such as using in-context learning (where examples of faithful reasoning are included in the prompt) or fine-tuning (where the model is trained on examples of faithful reasoning). However, a review of popular faithful CoT techniques by Harvard University researchers found that they have limited usefulness, and often decrease model accuracy.
CoT reasoning makes it easier to examine the reasoning processes that LLMs use to generate outputs. However, it has serious limitations. CoT is often unfaithful, and may become even more so as models get larger, or if we attempt to monitor them for bad behaviour. Although researchers are working on techniques to make CoT more faithful, we don’t yet have a complete solution.
AI is getting more powerful – and fast. We still don’t know how we’ll ensure that very advanced models are safe.
We designed a free, 2-hour course to help you understand how AI could transform the world in just a few years. Start learning today to join the conversation.
 | A guest post by
|