


When AI companies release a new model, they publish model cards detailing what it can and can’t do. Looking across major model releases, about half of evaluations measure general capabilities (e.g. coding, reasoning, writing) while the other half focus on dangerous capabilities: can the model help create bioweapons? Can it assist with cyberattacks? How persuasive is it at spreading misinformation?
Dangerous capability evals make sense for safety. We need to know how worried we should be about models causing harm.
But we’re missing benchmarks for specific positive safety things we want AI to do. Capabilities that could actively keep us safe or steer us toward better futures.
What beneficial evals would measure
Imagine if model cards included sections on how well AI systems perform at:
Safety research: Assisting with interpretability work, alignment research, or red-teaming other AI systems
Cyber defense: Not just penetration testing, but actually defending networks, detecting intrusions, and patching vulnerabilities
Pandemic preparedness: Accelerating vaccine development, optimising PPE distribution, or improving disease surveillance
Information integrity: Helping people find truth in a world full of mis/disinformation: fact-checking claims, detecting coordinated inauthentic behaviour, or surfacing reliable sources on contested topic
Models have graduated from ‘confidently wrong intern’ to ‘occasionally helpful new grad’, at least for some coding tasks. These evals and reinforcement learning (RL) environments could extend these into beneficial capabilities. If we’re heading toward a capabilities explosion, we need to ensure that beneficial capabilities outpace dangerous ones by a wide margin.
From evals to RL environments
Evals and RL environments are two sides of the same coin. An eval asks “can the model do X?” and produces a score. An RL environment asks the same question, but feeds that score back as a training signal.
In practice, this means a well-designed eval is most of the work to building an RL environment. If you can measure whether a model successfully identified the right papers, traced activations correctly, or generated a viable therapeutic drug candidate, you can turn that measurement into a reward signal. The eval’s scoring rubric becomes the RL environment’s reward function. The eval’s test cases become the RL environment’s training distribution.
A word of caution
Not everything that sounds safety-relevant actually is. Be careful that you’re measuring something genuinely useful for safety, not just general capabilities dressed up in safety language.
Getting models to be better at coding in Python is a general capability, not safety-specific. But improving models’ use of TransformerLens for interpretability research unblocks a specific safety-relevant bottleneck.
The goal is to create targets that, if hit, would actually make AI development go better, without inadvertently pushing general capabilities that could be misused.
How to build beneficial capability evals
Approach 1: Reproduce existing safety projects
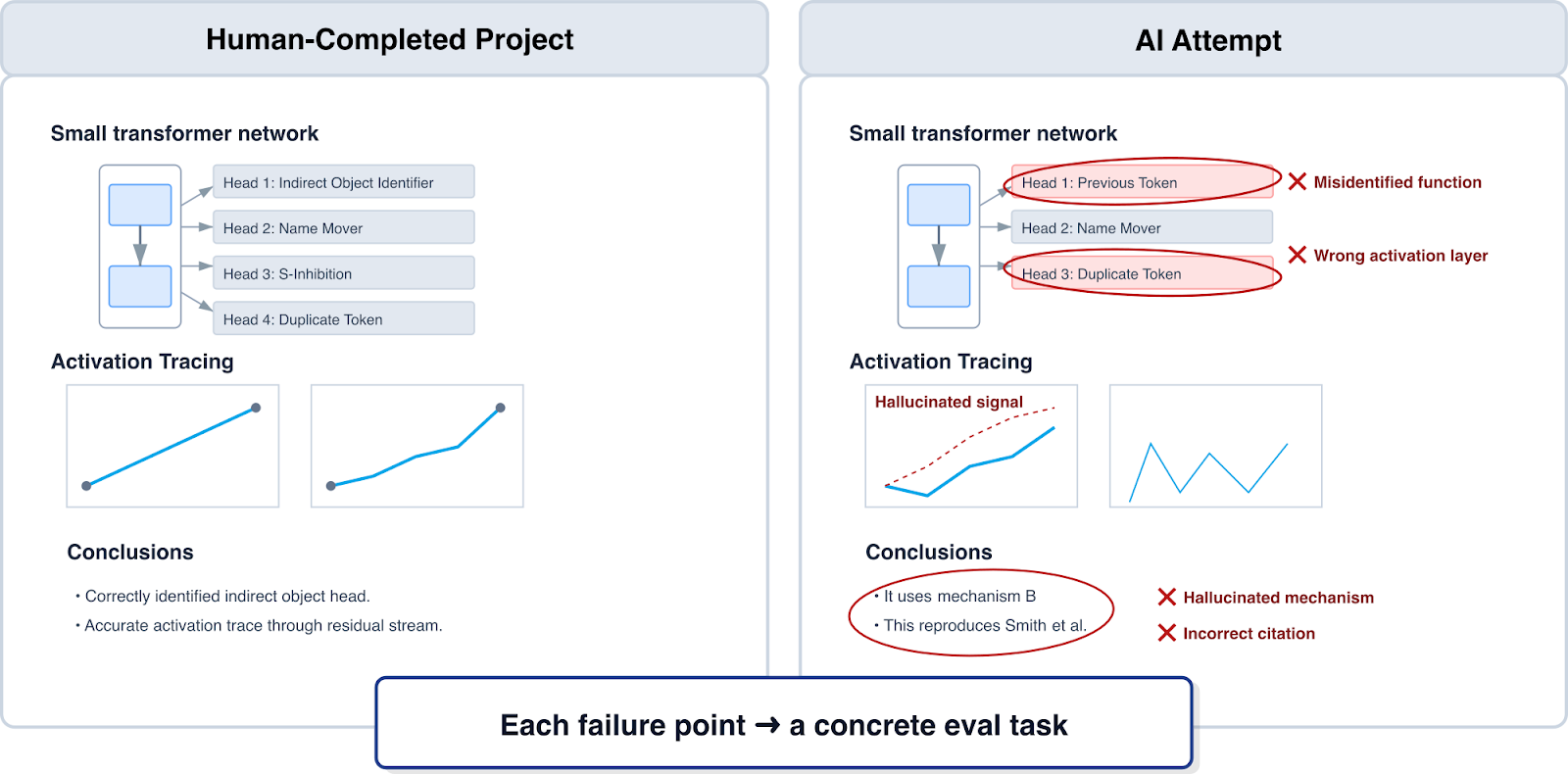
Take existing safety-relevant projects and try to get AI to reproduce them. Where does the model fail? Those failure points become eval problems you can measure against.
For example, BlueDot Impact runs courses where participants complete projects on AI safety, biosecurity, and other safety-relevant domains. Take a completed project — say, a mechanistic interpretability analysis of a small transformer — and see if a model can replicate it. If the model gets stuck on a specific step (maybe it can’t correctly identify attention head functions), that’s a concrete eval task.
This approach grounds you in real work that humans have already validated as useful.
Approach 2: Talk to safety researchers
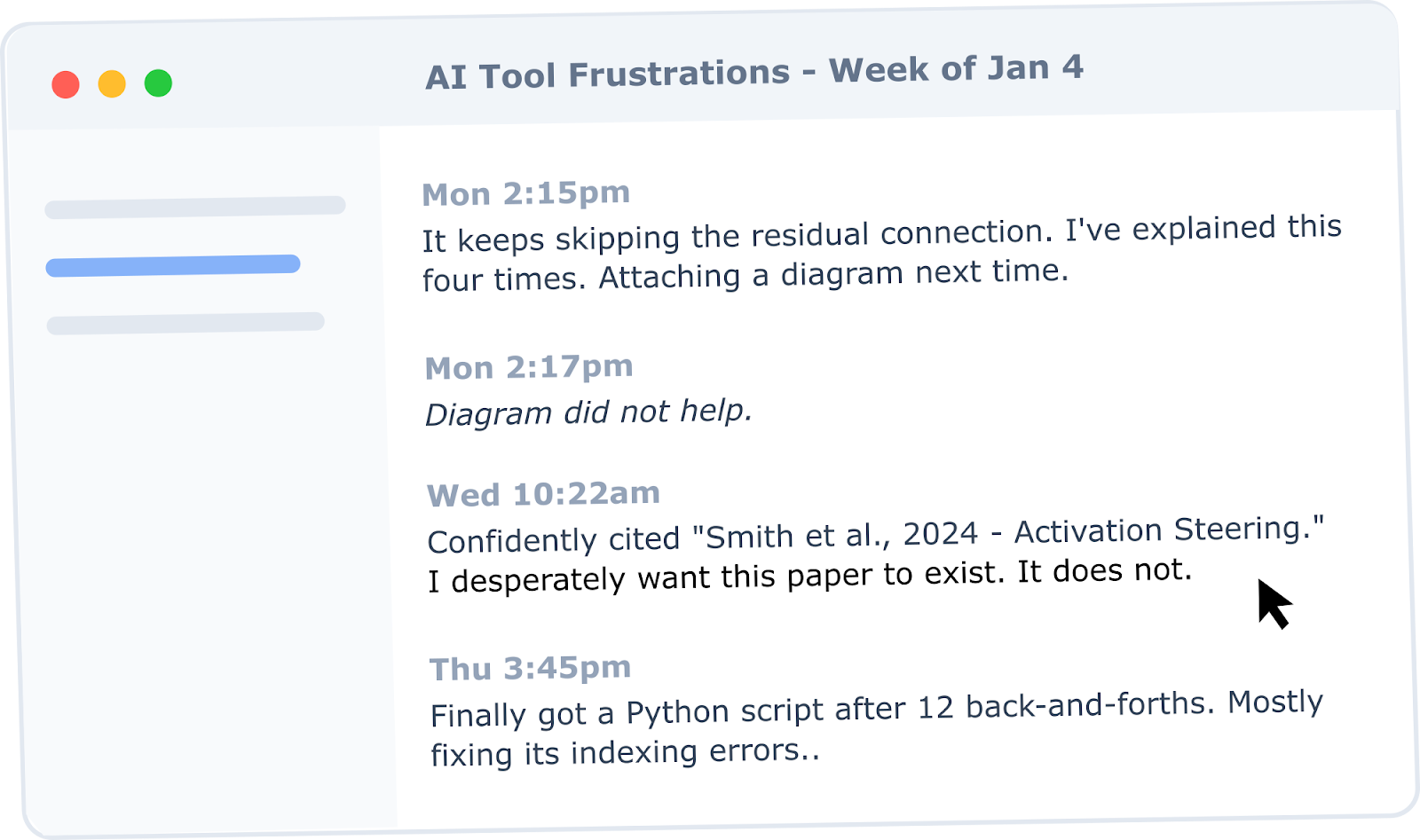
Go directly to people doing safety-relevant work. Ask them to keep a log for a couple of weeks: every time AI tools frustrate them, slow them down, or just can’t do something they need, write it down. Then collect these logs and look for patterns.
You might find things like: “Claude keeps hallucinating paper citations when I ask for related work,” or “I can’t get any model to correctly trace activations through residual stream connections,” or “It takes 10 back-and-forths to get the model to understand my codebase structure.”
These frustrations point directly to capability gaps. Turn them into evals.
Breaking down the work
Whatever approach you take, you’ll need to:
Map the process. Break down the safety-relevant task into all its component steps. For example, with vaccine development: literature review → identifying which parts the immune system can target → choosing an approach (mRNA, viral vector, etc.) → designing candidates → scaling up manufacturing → running clinical trials.
Prioritise. Figure out which parts of the pipeline are most important to work on first. Maybe running clinical trials is the biggest bottleneck or the literature review step that takes researchers months.
Define tasks. For each component, specify what success looks like in a way that’s measurable. For the literature review step, this might be: “Given a novel pathogen genome sequence, identify the 10 most relevant prior papers on similar pathogens, ranked by relevance to vaccine development”. Include a rubric for scoring relevance and completeness.
Build evaluation infrastructure. Many modern evals are “agent-evaluated”—you get one model to attempt a task, then use another model as a judge to verify whether specific conditions have been met. Inspect is a good framework for getting started with building evals. Consider submitting your work to inspect-evals to make it discoverable.
Iterating and improving. A key is desirable difficulty: we need evaluations that remain challenging and informative as capabilities improve. If in doubt, err on the side of too difficult.
Getting Your Work Used
Building good evals isn’t enough. You need companies to actually find and use them.
Make it discoverable: Publish on your blog, get it circulating on Twitter/X, or submit to relevant publications
Make it easy to run: Companies are more likely to adopt your eval if they can spin it up quickly
Work directly with companies: Offer to help them run it, troubleshoot issues, and interpret results
The business opportunity
Building good evals is a serious undertaking. No single person or team is going to create comprehensive positive capability benchmarks across all safety-relevant domains.
But there’s a business opportunity here. Companies will pay for RL environments: the Docker containers, code infrastructure, and carefully written rubrics for each task. A path here might be:
Start with a small batch or proof of concept
Pitch it to a company
If they’re interested, they might pay for a set of ~100 problems
They’ll QA the work, and if it’s good, they’ll ask for more
Two people working full-time could potentially (with a lot of coffee) get an initial batch done in a month.
Start building
Pick a safety-relevant domain you know, map the steps, find the bottlenecks, and build something. You can also:
Apply to our incubator weeks.
Use or apply to the Technical AI Safety Project sprint
Learn more about plans to make AI go well on the AGI strategy course.
Tag @BlueDotImpact on Twitter or LinkedIn. We’d love to see what you build!
 | A guest post by
|
This is helpful, insightful, and actionable - thank you for sharing these ideas.