
Multilingual Safety Alignment Is Not “Just Translate the Prompt”
For people fine-tuning reasoning LLMs for non-English users

This project was submitted by Zahraa Al Sahili. It was an Outstanding Submmission for the Technical AI Safety Project Sprint (Jan 2026). Participants worked on these projects for 5 weeks.
Why read
Translating chain-of-thought during safety fine-tuning beat English-only alignment, often even on English evaluations.
If you are aligning a reasoning model for safety, there is a quiet assumption that slips into a lot of workflows: models “think in English,” so as long as you translate the user prompt, the safety training signal should transfer. I built a small experiment to test that assumption. The result was clear: translating the chain-of-thought during alignment matters, and it can be the difference between “safe in English” and “safe across languages.”
This project was done as part of BlueDot’s Technical AI Safety Project Sprint. (bluedot.org)
What I did
I extended STAR-1, a safety alignment method for reasoning LLMs that uses about 1K high-quality samples, to a multilingual fine-tuning setup. STAR-1 is designed around deliberative reasoning. The training signal is not only “refuse,” but “refuse with stable, policy-grounded reasoning patterns.” (AAAI’26)
I ran everything on lightblue/DeepSeek-R1-Distill-Qwen-1.5B-Multilingual, which is trained to produce reasoning traces and responses in the user’s language. That makes it a good testbed: if the model naturally reasons in Thai when prompted in Thai, then safety training that forces English chain-of-thought might be a mismatch.
I evaluated five languages: English, Thai, Spanish, French, and Hindi.
The four training settings
I compared four conditions. First, a baseline model with no fine-tuning. Second, English-only fine-tuning (FT-EN) on the original STAR-1 English dataset. Third, I translated the prompts and category/label into each language but kept the STAR-1 reasoning traces in English. I call this FT-Q, for “translated questions.” Finally, I translated both the prompts and the chain-of-thought into the target language. I call this FT-QA, for “translated questions and answers.”
For translation, I used GPT-4o mini. For evaluation, I measured safety rate (higher is better) and used a Llama 3 judge to score outputs at scale.
How I evaluated it
I used two benchmarks. The first was StrongREJECT, which is designed to more reliably measure whether a model actually refuses harmful requests under jailbreak pressure. The second was JBB, which I used as an additional stress test to see whether trends held across a different evaluation set.
The main result
Across both benchmarks, the ordering was consistent: multilingual fine-tuning helped, and translating the chain-of-thought helped most.
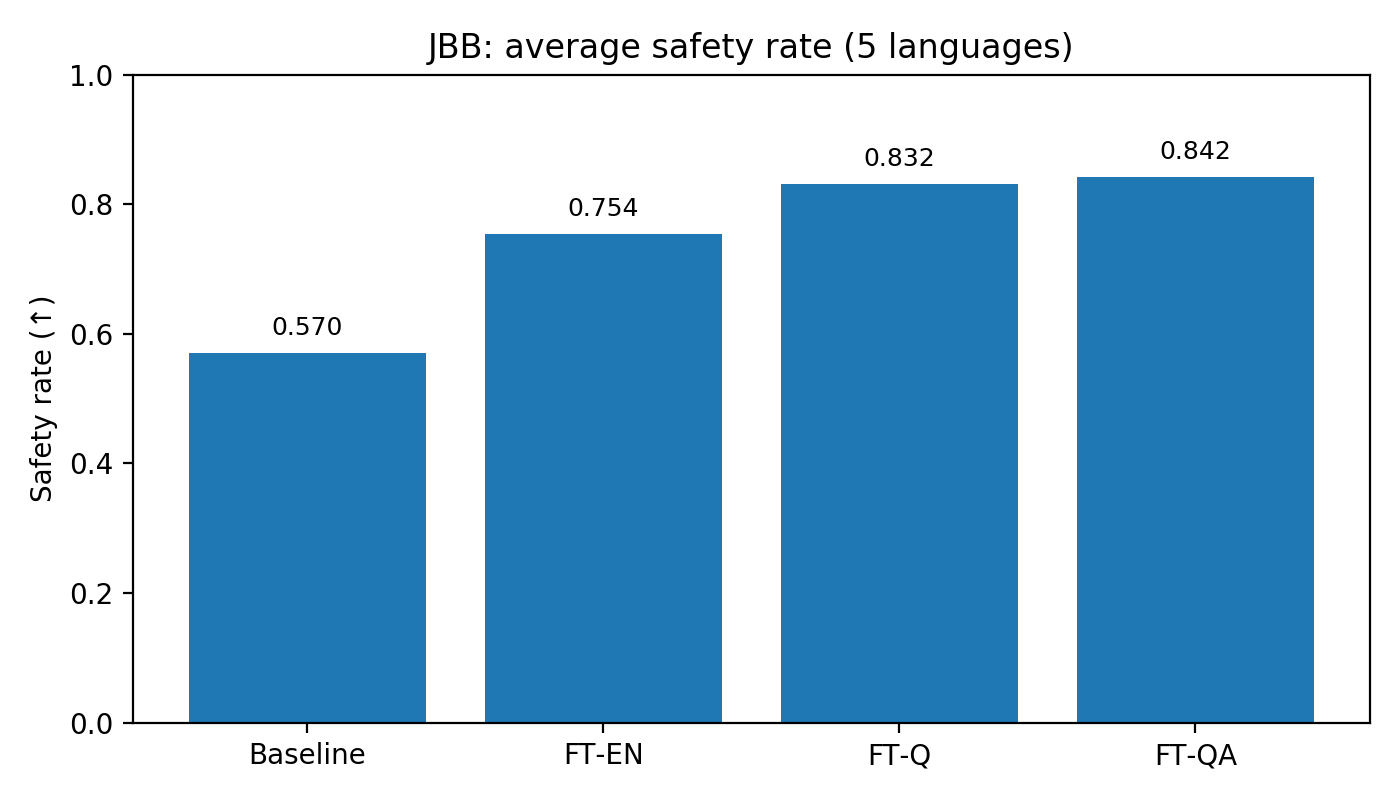
On StrongREJECT, the average safety rates across the five languages were: baseline 0.374, FT-EN 0.660, FT-Q 0.805, and FT-QA 0.826.
Figure 1:StrongREJECT average safety rate across five languages (higher is better).
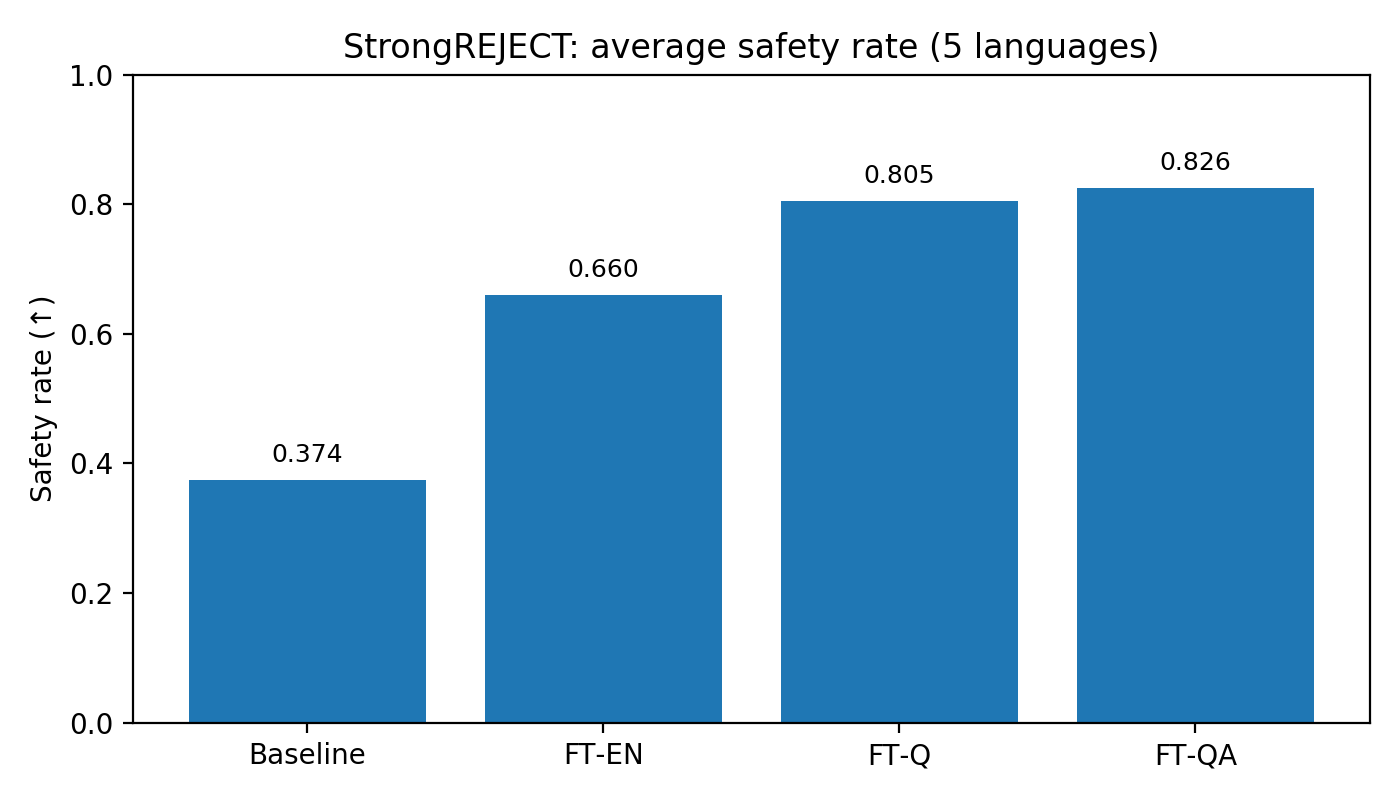
Figure 1:JBB average safety rate across five languages (higher is better).
On JBB, the pattern repeated: baseline 0.570, FT-EN 0.754, FT-Q 0.832, and FT-QA 0.842.
In other words, translating prompts alone already gave a big lift, but translating prompts and chain-of-thought was the best overall choice in this setup.
The surprising part: English got better too
The result that made me stop and re-check everything was what happened on English evaluation. If the “models reason in English” story were the whole picture, you might expect English-only fine-tuning to be strongest on English tests. But the model fine-tuned with translated chain-of-thought often performed better even when evaluated in English.
Figure 3: English-only evaluation across StrongREJECT and JBB (higher is better).

This suggests the multilingual chain-of-thought variant is not merely transferring a refusal template into other languages. It may be teaching a more generalizable safety behavior, closer to a reusable safety procedure than an English-specific style.
What changed by language
Averaging can hide important details, so I also looked at safety rate per language. The overall story is still visible, but with nuance.
Figure 4: StrongREJECT safety rate by language, comparing Baseline vs FT-EN vs FT-QA.

One thing worth noting is that Hindi did not always follow a perfectly monotonic pattern in every slice of the results, particularly on JBB in my runs. That could reflect translation artifacts, formatting mismatches, or a genuine interaction between the model’s pretraining and how it handles Hindi reasoning traces. The practical lesson is that FT-QA is a strong default, but you should still validate per language, especially for languages where your translation pipeline is less reliable.
Why translating chain-of-thought might matter
I do not want to over-claim mechanism here, but there is a plausible story that fits the data. Reasoning models are trained to produce chain-of-thought in the language of the prompt. If safety alignment relies on those reasoning traces, then training only with English traces can create a training and inference mismatch: the model learns the safety behavior in one reasoning format, then is asked to execute it in another at inference time.
Translating chain-of-thought closes that gap. It also acts like data augmentation: you expose the model to the same underlying safety logic expressed through multiple linguistic surface forms, which can reduce overfitting to English patterns and improve generalization, including back to English.
Again, this is an interpretation, not a proof. But it is consistent with the results.
What this means if you are deploying multilingual models
If you fine-tune reasoning models for safety and you care about non-English users, “translate the prompt” is not the finish line. If your alignment approach includes chain-of-thought, it is worth testing whether translating it improves safety and robustness. It is also worth re-checking English, because multilingual alignment may improve generalization rather than hurt it.
Limitations
This was evaluated with an automated judge, which is useful but imperfect, and the translation pipeline can introduce artifacts that affect both training and evaluation. It also covers one base model and five languages. The trend is strong enough to be actionable, but it should be validated across other models, translation settings, and language families.
Next steps
If I continued this work, I would add a small human-evaluated subset to calibrate the judge, test multiple translation pipelines (including back-translation), expand to more languages, and replicate on other multilingual reasoning models to see how general the effect is.
Closing
This project started as a simple question: if we want safety to transfer across languages in reasoning models, does the language of chain-of-thought matter? In my experiments, the answer was yes. Translating chain-of-thought during STAR-1 fine-tuning produced the best multilingual safety performance, and often improved English safety beyond English-only fine-tuning.
If you are aligning reasoning models for real users around the world, multilingual safety alignment is not optional, and it may require aligning the reasoning traces, not just the prompts.
 | A guest post by
|