

Many people worry about risks from advanced AI, from loss-of-control to misuse by bad actors. Yet today’s Large Language Models (LLMs) provide helpful, humanlike responses and usually refuse requests for harmful outputs. How have AI developers achieved this?
The main technique used to ensure that LLMs operate according to human intentions is Reinforcement Learning from Human Feedback (RLHF). It’s important to note that although RLHF is mostly effective for controlling today’s models, AI companies do not expect that it will scale to AIs with superhuman capabilities. We’ve written a separate post explaining why.
In this post, we’ll give a simple overview of how RLHF works.
What is RLHF?
RLHF is a method for optimising AI models to produce outputs that humans prefer. It is the most resource-intensive stage in the alignment process, and is sometimes preceded by supervised fine-tuning (SFT).
Alignment techniques like RLHF and STF are important because “raw” LLMs are simply trained to predict the next word on a large dataset of internet text. But there’s plenty of harmful, untrue and unhelpful content on the internet! This means that predicting the next word can often produce responses that do not benefit users.
To better align LLMs with their users, we get human annotators to provide feedback on LLM outputs. This feedback becomes the dataset that we use to train a reward model, which is then integrated with the main model in order to positively or negatively reinforce its behaviour.
How does RLHF work?
Here’s a step-by-step breakdown of the RLHF process:
We start with a pre-trained, “raw” model. This model may also have undergone some initial alignment in the form of SFT.
Now, we need to curate a set of prompts that we’ll use to generate model responses. These can either be written by specially-hired contractors or lifted from user interactions with existing models. For example, in its paper introducing the RLHF method, OpenAI used around 10,000 contractor-written prompts and 40,000 from users in order to train a reward model for InstructGPT.
Next, we get the model to respond to these prompts. This requires generating multiple responses per prompt, so that humans can rank them based on preference. Each prompt used in the training of InstructGPT had between 4 and 9 responses.
Once we have a set of AI outputs, we can start gathering human feedback. A group of human contractors are shown outputs and asked to evaluate them in a number of different ways. For example, they could be asked to rank different answers to the same prompt, give each prompt an absolute score, or flag prompts for inappropriate content. Here’s an example of the interface that labelers saw when giving feedback to train InstructGPT:
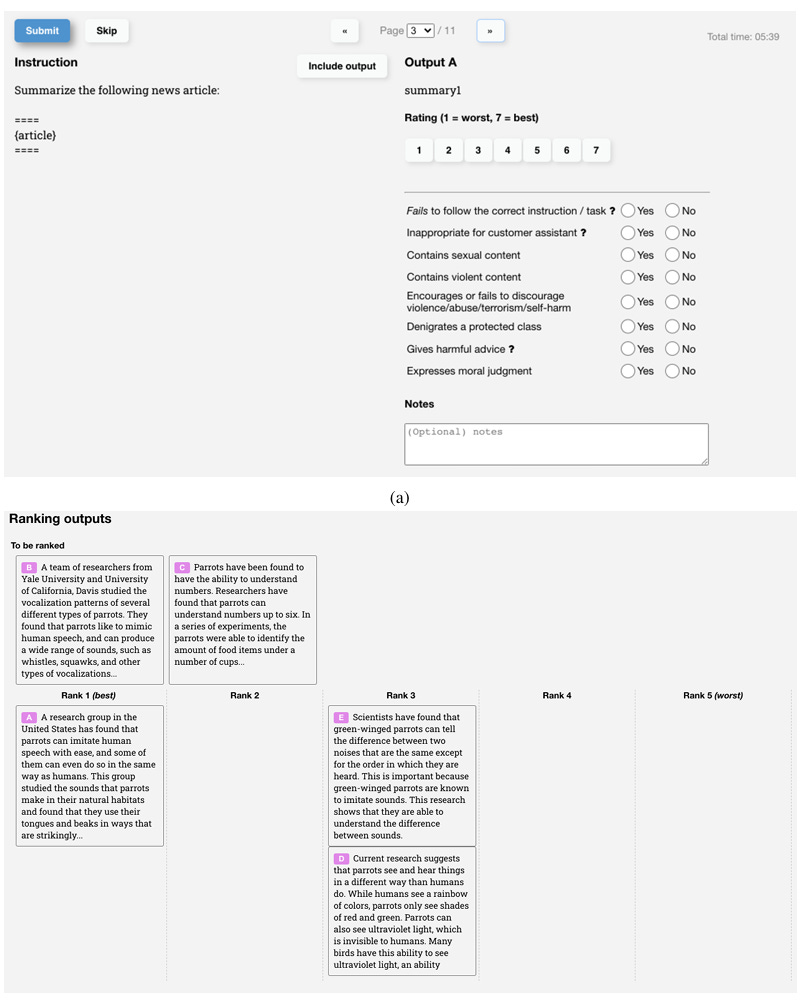
Source: Training language models to follow instructions with human feedback
This human feedback data is aggregated and used to train the reward model. The reward model is designed to output a score for a given output, according to how well it aligns with human preferences.
Now, we fine-tune the original model using scores from the reward model. We randomly select prompts from the larger set, get our model to output responses, and have them scored by the reward model. These scores are used to update our original model so that it produces more aligned responses.
Can we align superhuman models using RLHF?
RLHF is the most effective method we have for ensuring that AIs produce outputs that are aligned with their users. But even for existing models – which have yet to exceed human capabilities across a broad range of domains – RLHF cannot reliably prevent unaligned behaviour. For example, AI models can be jailbroken to output dangerous information. They sometimes lie to users, tell them what they want to hear, and can even construct long-run plans to preserve their values. These issues may become more unmanageable as AIs become more capable.
RLHF relies on humans being able to usefully evaluate AI outputs. But if models become superhuman, they may produce outputs that we don’t understand well enough to assess. This is one of the core challenges of scaling RLHF to align very advanced models. Some techniques such as recursive reward modelling and AI debate aim to address this problem, but also have important limitations.
We’ve written more about these issues in our blog post on problems with RLHF for AI safety.
AI is getting more powerful – and fast. We still don’t know how we’ll ensure that very advanced models are safe.
We designed a free, 2-hour course to help you understand how AI could transform the world in just a few years. Start learning today to join the conversation.
 | A guest post by
|